

打败李世乭的AlphaGo,被弟弟AlphaGo Zero打败了,成绩是0-100
去年,有个小孩读遍人世所有的棋谱,辛勤打谱,苦思冥想,棋艺精进,4-1打败世界冠军李世石,从此人间无敌手。他的名字叫 AlphaGo(阿法狗)。
今年,他的弟弟只靠一副棋盘和黑白两子,没看过一个棋谱,也没有一个人指点,从零开始,自娱自乐,自己参悟,100-0打败哥哥 AlphaGo 。他的名字叫 AlphaGo Zero(阿法元) 。
DeepMind 这项伟大的突破,今天以 Mastering the game of Go without human knowledge 为题,发表于 Nature,引起轰动。知社特邀国内外几位人工智能专家,给予深度解析和点评。
自学三天,100-0击溃阿法狗

Nature今天上线的这篇重磅论文,详细介绍了谷歌DeepMind团队最新的研究成果。
人工智能的一项重要目标,是在没有任何先验知识的前提下,通过完全的自学,在极具挑战的领域,达到超人的境地。
去年,阿法狗(AlphaGo)代表人工智能在围棋领域首次战胜了人类的世界冠军,但其棋艺的精进,是建立在计算机通过海量的历史棋谱学习参悟人类棋艺的基础之上,进而自我训练,实现超越。
可是今天,我们发现,人类其实把阿法狗教坏了!
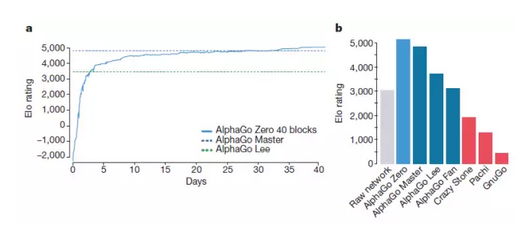
新一代的阿法元(AlphaGo Zero), 完全从零开始,不需要任何历史棋谱的指引,更不需要参考人类任何的先验知识,完全靠自己一个人强化学习(reinforcement learning)和参悟, 棋艺增长远超阿法狗,百战百胜,击溃阿法狗100-0。
达到这样一个水准,阿法元只需要在4个TPU上,花三天时间,自己左右互搏490万棋局。而它的哥哥阿法狗,需要在48个TPU上,花几个月的时间,学习三千万棋局,才打败人类。

David Silver博士,AlphaGo项目负责人
这篇论文的第一和通讯作者是DeepMind的David Silver博士, 阿法狗项目负责人。他介绍说阿法元远比阿法狗强大,因为它不再被人类认知所局限,而能够发现新知识,发展新策略:
This technique is more powerful than previous versions of AlphaGo because it is no longer constrained by the limits of human knowledge. Instead, it is able to learn tabula rasa from the strongest player in the world: AlphaGo itself. AlphaGo Zero also discovered new knowledge, developing unconventional strategies and creative new moves that echoed and surpassed the novel techniques it played in the games against Lee Sedol and Ke Jie.
DeepMind联合创始人和CEO则说这一新技术能够用于解决诸如蛋白质折叠和新材料开发这样的重要问题:
AlphaGo Zero is now the strongest version of our program and shows how much progress we can make even with less computing power and zero use of human data. Ultimately we want to harness algorithmic breakthroughs like this to help solve all sorts of pressing real world problems like protein folding or designing new materials.
美国的两位棋手在Nature对阿法元的棋局做了点评:
它的开局和收官和专业棋手的下法并无区别,人类几千年的智慧结晶,看起来并非全错。但是中盘看起来则非常诡异:
the AI’s open¬ing choices and end-game methods have converged on ours — seeing it arrive at our sequences from first principles suggests that we haven’t been on entirely the wrong track. By contrast, some of its middle-game judgements are truly mysterious.
无师自通,关键技术是哪些?
为更深入了解阿法元的技术细节,知社采访了美国杜克大学人工智能专家陈怡然教授。他向知社介绍说:
DeepMind最新推出的AlphaGo Zero降低了训练复杂度,摆脱了对人类标注样本(人类历史棋局)的依赖,让深度学习用于复杂决策更加方便可行。我个人觉得最有趣的是证明了人类经验由于样本空间大小的限制,往往都收敛于局部最优而不自知(或无法发现),而机器学习可以突破这个限制。之前大家隐隐约约觉得应该如此,而现在是铁的量化事实摆在面前!
他进一步解释道:
这篇论文数据显示学习人类选手的下法虽然能在训练之初获得较好的棋力,但在训练后期所能达到的棋力却只能与原版的AlphaGo相近,而不学习人类下法的AlphaGo Zero最终却能表现得更好。这或许说明人类的下棋数据将算法导向了局部最优(local optima),而实际更优或者最优的下法与人类的下法存在一些本质的不同,人类实际’误导’了AlphaGo。有趣的是如果AlphaGo Zero放弃学习人类而使用完全随机的初始下法,训练过程也一直朝着收敛的方向进行,而没有产生难以收敛的现象。
阿法元是如何实现无师自通的呢? 杜克大学博士研究生吴春鹏向知社介绍了技术细节:
之前战胜李世石的AlphaGo基本采用了传统增强学习技术再加上深度神经网络DNN完成搭建,而AlphaGo Zero吸取了最新成果做出了重大改进。
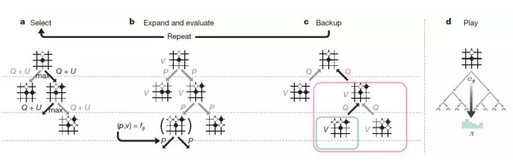
首先,在AlphaGo Zero出现之前,基于深度学习的增强学习方法按照使用的网络模型数量可以分为两类: 一类使用一个DNN"端到端"地完成全部决策过程(比如DQN),这类方法比较轻便,对于离散动作决策更适用; 另一类使用多个DNN分别学习policy和value等(比如之前战胜李世石的AlphaGoGo),这类方法比较复杂,对于各种决策更通用。此次的AlphaGo Zero综合了二者长处,采用类似DQN的一个DNN网络实现决策过程,并利用这个DNN得到两种输出policy和value,然后利用一个蒙特卡罗搜索树完成当前步骤选择。
其次,AlphaGo Zero没有再利用人类历史棋局,训练过程从完全随机开始。随着近几年深度学习研究和应用的深入,DNN的一个缺点日益明显: 训练过程需要消耗大量人类标注样本,而这对于小样本应用领域(比如医疗图像处理)是不可能办到的。所以Few-shot learning和Transfer learning等减少样本和人类标注的方法得到普遍重视。AlphaGo Zero是在双方博弈训练过程中尝试解决对人类标注样本的依赖,这是以往没有的。
第三,AlphaGo Zero在DNN网络结构上吸收了最新进展,采用了ResNet网络中的Residual结构作为基础模块。近几年流行的ResNet加大了网络深度,而GoogLeNet加大了网络宽度。之前大量论文表明,ResNet使用的Residual结构比GoogLeNet使用的Inception结构在达到相同预测精度条件下的运行速度更快。AlphaGo Zero采用了Residual应该有速度方面的考虑。
杜克大学博士研究生谢知遥对此做了进一步阐述:
DeepMind的新算法AlphaGo Zero开始摆脱对人类知识的依赖:在学习开始阶段无需先学习人类选手的走法,另外输入中没有了人工提取的特征 。
在网络结构的设计上,新的算法与之前的AlphaGo有两个大的区别。首先,与之前将走子策略(policy)网络和胜率值(value)网络分开训练不同,新的网络结构可以同时输出该步的走子策略(policy)和当前情形下的胜率值(value)。实际上 policy与value网络相当于共用了之前大部分的特征提取层,输出阶段的最后几层结构仍然是相互独立的。训练的损失函数也同时包含了policy和value两部分。这样的显然能够节省训练时间,更重要的是混合的policy与value网络也许能适应更多种不同情况。
另外一个大的区别在于特征提取层采用了20或40个残差模块,每个模块包含2个卷积层。与之前采用的12层左右的卷积层相比,残差模块的运用使网络深度获得了很大的提升。AlphaGo Zero不再需要人工提取的特征应该也是由于更深的网络能更有效地直接从棋盘上提取特征。根据文章提供的数据,这两点结构上的改进对棋力的提升贡献大致相等。
因为这些改进,AlphaGo Zero的表现和训练效率都有了很大的提升,仅通过4块TPU和72小时的训练就能够胜过之前训练用时几个月的原版AlphaGo。在放弃学习人类棋手的走法以及人工提取特征之后,算法能够取得更优秀的表现,这体现出深度神经网络强大的特征提取能力以及寻找更优解的能力。更重要的是,通过摆脱对人类经验和辅助的依赖,类似的深度强化学习算法或许能更容易地被广泛应用到其他人类缺乏了解或是缺乏大量标注数据的领域。
AlphaGo优化意义何在?人工智能的将来又在哪里?
这个工作意义何在呢?人工智能专家、美国北卡罗莱纳大学夏洛特分校洪韬教授也对知社发表了看法:
我非常仔细从头到尾读了这篇论文。首先要肯定工作本身的价值。从用棋谱(supervised learning)到扔棋谱,是重大贡献(contribution)!干掉了当前最牛的棋手(变身前的阿法狗),是advancing state-of-the-art 。神经网络的设计和训练方法都有改进,是创新(novelty)。从应用角度,以后可能不再需要耗费人工去为AI的产品做大量的前期准备工作,这是其意义(significance)所在!
接着,洪教授也简单回顾了人工神经网络的历史:
人工神经网络在上世纪四十年代就出来了,小火了一下就撑不下去了,其中一个原因是大家发现这东西解决不了“异或问题”,而且训练起来太麻烦。到了上世纪七十年代,Paul Werbos读博时候拿backpropagation的算法来训练神经网络,提高了效率,用多层神经网络把异或问题解决了,也把神经网络带入一个新纪元。上世纪八九十年代,人工神经网络的研究迎来了一场大火,学术圈发了成千上万篇关于神经网络的论文,从设计到训练到优化再到各行各业的应用。
Jim Burke教授,一个五年前退休的IEEE Life Fellow,曾经讲过那个年代的故事:去开电力系统的学术会议,每讨论一个工程问题,不管是啥,总会有一帮人说这可以用神经网络解决,当然最后也就不了了之了。简单的说是大家挖坑灌水吹泡泡,最后没啥可忽悠的了,就找个别的地儿再继续挖坑灌水吹泡泡。上世纪末的学术圈,如果出门不说自己搞神经网络的都不好意思跟人打招呼,就和如今的深度学习、大数据分析一样。
然后,洪教授对人工智能做了并不十分乐观的展望:
回到阿法狗下棋这个事儿,伴随着大数据的浪潮,数据挖掘、机器学习、神经网络和人工智能突然间又火了起来。这次火的有没有料呢?我认为是有的,有海量的数据、有计算能力的提升、有算法的改进。这就好比当年把backpropagation用在神经网络上,的确是个突破。
最终这个火能烧多久,还得看神经网络能解决多少实际问题。二十年前的大火之后,被神经网络“解决”的实际问题寥寥无几,其中一个比较知名的是电力负荷预测问题,就是用电量预测,刚好是我的专业。由于当年神经网络过于火爆,导致科研重心几乎完全离开了传统的统计方法。等我刚进入这个领域做博士论文的时候,就拿传统的多元回归模型秒杀了市面上的各种神经网络遗传算法的。我一贯的看法,对于眼前流行的东西,不要盲目追逐,要先审时度势,看看自己擅长啥、有啥积累,看准了坑再跳。
美国密歇根大学人工智能实验室主任Satinder Singh也表达了和洪教授类似的观点:这并非任何结束的开始,因为人工智能和人甚至动物相比,所知所能依然极端有限:
This is not the beginning of any end because AlphaGo Zero, like all other successful AI so far, is extremely limited in what it knows and in what it can do compared with humans and even other animals.
不过,Singh教授仍然对阿法元大加赞赏:这是一项重大成就, 显示强化学习而不依赖人的经验,可以做的更好:
The improvement in training time and computational complex¬ity of AlphaGo Zero relative to AlphaGo, achieved in about a year, is a major achieve¬ment… the results suggest that AIs based on reinforcement learning can perform much better than those that rely on human expertise.
陈怡然教授则对人工智能的未来做了进一步的思考:
AlphaGo Zero没有使用人类标注,只靠人类给定的围棋规则,就可以推演出高明的走法。有趣的是,我们还在论文中看到了AlphaGo Zero掌握围棋的过程。比如如何逐渐学会一些常见的定式与开局方法 ,如第一手点三三。相信这也能对围棋爱好者理解AlphaGo的下棋风格有所启发。
除了技术创新之外,AlphaGo Zero又一次引发了一个值得所有人工智能研究者思考的问题: 在未来发展中,我们究竟应该如何看待人类经验的作用。在AlphaGo Zero自主学会的走法中,有一些与人类走法一致,区别主要在中间相持阶段。AlphaGo Zero已经可以给人类当围棋老师,指导人类思考之前没见过的走法,而不用完全拘泥于围棋大师的经验。也就是说AlphaGo Zero再次打破了人类经验的神秘感,让人脑中形成的经验也是可以被探测和学习的。
陈教授最后也提出一个有趣的命题:
未来我们要面对的一个挑战可能就是: 在一些与日常生活有关的决策问题上,人类经验和机器经验同时存在,而机器经验与人类经验有很大差别,我们又该如何去选择和利用呢?
不过David Silver对此并不担心,而对未来充满信心。他指出:
If similar techniques can be applied to other structured problems, such as protein folding, reducing energy consumption or searching for revolutionary new materials, the resulting breakthroughs have the potential to positively impact society.

不深思则不能造于道。不深思而得者,其得易失。
名人名言- 曾国藩
- By 知社学术圈
- 2017-10-19
- 14046
- 公司新闻,网站开发,网站设计,UI